Introduction
Description
These are the results for the 2014 running of the Singing Voice Separation task set. For more information about this task set please refer to the 2014:Singing Voice Separation page.
Legend
| Submission code
|
Submission name
|
Abstract PDF
|
Contributors
|
| GW1
|
Bayesian Singing-Voice Separation |
PDF |
Guan-Xiang Wang, Po-Kai Yang, Chung-Chien Hsu, Jen-Tzung Chien
|
| HKHS1
|
Singing-Voice Separation using Deep Recurrent Neural Networks |
PDF |
Po-Sen Huang, Minje Kim, Mark Hasegawa-Johnson, Paris Smaragdis
|
| HKHS2
|
Singing-Voice Separation using Deep Recurrent Neural Networks |
PDF |
Po-Sen Huang, Minje Kim, Mark Hasegawa-Johnson, Paris Smaragdis
|
| HKHS3
|
Singing-Voice Separation using Deep Recurrent Neural Networks |
PDF |
Po-Sen Huang, Minje Kim, Mark Hasegawa-Johnson, Paris Smaragdis
|
| IIY1
|
Singing Voice Separation and Vocal F0 Estimation based on Robust PCA and Subharmonic Summation |
PDF |
Yukara Ikemiya, Katsutoshi Itoyama, Kazuyoshi Yoshii
|
| IIY2
|
Singing Voice Separation and Vocal F0 Estimation based on Robust PCA and Subharmonic Summation |
PDF |
Yukara Ikemiya, Katsutoshi Itoyama, Kazuyoshi Yoshii
|
| JL1
|
Singing Voice Separation Based on Sparse Nature and Spectral/Temporal Discontinuity |
PDF |
Il-Young Jeong, Kyogu Lee
|
| LFR1
|
Kernel Additive Modelling with light models |
- |
Antoine Liutkus, Derry Fitzgerald, Zafar Rafii
|
| RNA1
|
Singing Voice Separation using Adaptive Window Harmonic Sinusoidal Modeling |
PDF |
Preeti Rao, Nagesh Nayak, Sharath Adavanne
|
| RP1
|
REPET-SIM for Singing Voice Separation |
PDF |
Zafar Rafii, Bryan Pardo
|
| YC1
|
MIREX 2014 Submission for Singing Voice Separation |
PDF |
Frederick Yen, Tai-Shih Chi
|
Evaluation Criteria
GNSDR = Global Normalized Signal-to-Distortion Ratio
NSDR = Normalized Signal-to-Distortion Ratio
SIR = Signal-to-Interference Ratio
SAR = Signal-to-Artifacts Ratio
Summary
Summary Results
| Algorithm |
Voice GNSDR (dB) |
Music GNSDR (dB) |
Runtime (hh)
|
| GW1 |
2.8861 |
5.2549 |
24
|
| HKHS1 |
-1.3988 |
0.3483 |
06
|
| HKHS2 |
-1.9413 |
0.5239 |
06
|
| HKHS3 |
-2.4807 |
0.1414 |
06
|
| IIY1 |
4.2190 |
7.7893 |
02
|
| IIY2 |
4.4764 |
7.8661 |
02
|
| JL1 |
4.1564 |
5.6304 |
01
|
| LFR1 |
0.6499 |
3.0867 |
03
|
| RNA1 |
3.6915 |
7.3153 |
06
|
| RP1 |
2.8602 |
5.0306 |
01
|
| YC1 |
-0.8202 |
-3.1150 |
13
|
NSDR
For the Singing Voice (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
2.8861 |
3.4543 |
-7.1344 |
12.819 |
2.5745 |
| HKHS1 |
-1.3988 |
3.0574 |
-9.4234 |
4.292 |
-1.2971 |
| HKHS2 |
-1.9413 |
3.2899 |
-11.309 |
7.2794 |
-1.4234 |
| HKHS3 |
-2.4807 |
3.8173 |
-12.272 |
9.7879 |
-1.5772 |
| IIY1 |
4.219 |
3.2378 |
-3.4536 |
15.517 |
4.4345 |
| IIY2 |
4.4764 |
3.0584 |
-2.3763 |
16.212 |
4.2927 |
| JL1 |
4.1564 |
3.9819 |
-3.9431 |
15.822 |
3.7558 |
| LFR1 |
0.64992 |
3.7455 |
-9.6199 |
7.4555 |
0.97393 |
| RNA1 |
3.6915 |
3.4319 |
-1.8064 |
14.38 |
3.4024 |
| RP1 |
2.8602 |
2.7926 |
-3.771 |
12.105 |
2.4553 |
| YC1 |
-0.82015 |
3.4857 |
-8.7424 |
7.9435 |
-0.42864 |
download these results as csv
For the Music Accompaniment (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
5.2549 |
4.0553 |
-0.792 |
16.155 |
5.0222 |
| HKHS1 |
0.34825 |
2.207 |
-5.7359 |
6.1051 |
0.33855 |
| HKHS2 |
0.52394 |
2.5029 |
-6.1304 |
6.0994 |
0.90947 |
| HKHS3 |
0.14144 |
2.3196 |
-6.3693 |
5.8651 |
0.55883 |
| IIY1 |
7.7893 |
3.0938 |
-4.0068 |
13.949 |
8.1274 |
| IIY2 |
7.8661 |
3.5329 |
-2.4807 |
15.082 |
8.7023 |
| JL1 |
5.6304 |
4.0732 |
-0.91101 |
17.648 |
5.5284 |
| LFR1 |
3.0867 |
2.6421 |
-6.9241 |
10.887 |
2.9156 |
| RNA1 |
7.3153 |
2.9143 |
-5.9455 |
13.753 |
7.5214 |
| RP1 |
5.0306 |
3.004 |
-0.99542 |
15.424 |
4.9872 |
| YC1 |
-3.115 |
3.6797 |
-12.229 |
3.5503 |
-2.9997 |
download these results as csv
Boxplots
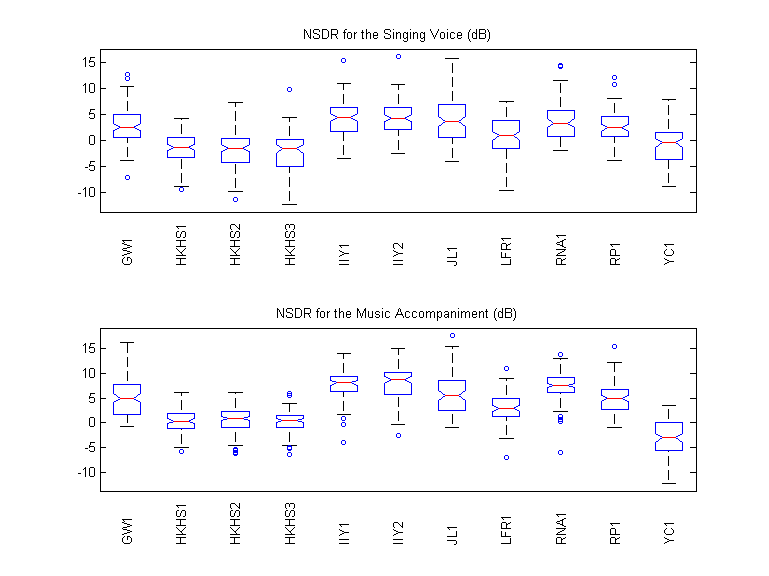
SIR
For the Singing Voice (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
6.9844 |
9.43 |
-26.961 |
18.215 |
8.8768 |
| HKHS1 |
6.7499 |
10.673 |
-30.345 |
23.034 |
7.058 |
| HKHS2 |
8.3009 |
11.705 |
-32.287 |
29.393 |
7.8647 |
| HKHS3 |
7.7489 |
12.137 |
-30.839 |
28.544 |
8.9649 |
| IIY1 |
15.472 |
11.954 |
-28.445 |
32.446 |
18.307 |
| IIY2 |
13.267 |
11.466 |
-30.369 |
30.901 |
16.314 |
| JL1 |
9.6169 |
9.6173 |
-24.122 |
24.341 |
11.755 |
| LFR1 |
10.454 |
10.442 |
-26.952 |
23.638 |
13.042 |
| RNA1 |
16.323 |
10.951 |
-24.713 |
34.263 |
18.799 |
| RP1 |
7.2958 |
9.7631 |
-28.981 |
20.303 |
9.7841 |
| YC1 |
10.873 |
10.809 |
-28.646 |
27.301 |
12.837 |
download these results as csv
For the Music Accompaniment (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
6.96 |
13.076 |
-12.643 |
42.653 |
4.3054 |
| HKHS1 |
1.4953 |
10.084 |
-13.232 |
38.909 |
-1.4525 |
| HKHS2 |
2.4162 |
10.465 |
-9.9978 |
34.081 |
-0.51852 |
| HKHS3 |
0.90212 |
9.7862 |
-11.02 |
34.345 |
-0.66779 |
| IIY1 |
12.44 |
8.1972 |
-0.61968 |
41.502 |
11.163 |
| IIY2 |
14.301 |
8.3307 |
0.49447 |
41.767 |
13.809 |
| JL1 |
5.6509 |
10.636 |
-13.16 |
39.5 |
4.3978 |
| LFR1 |
4.4493 |
10.109 |
-11.445 |
41.717 |
2.0394 |
| RNA1 |
12.938 |
8.5096 |
-1.3967 |
40.34 |
11.979 |
| RP1 |
5.5158 |
10.417 |
-11.092 |
44.235 |
4.6256 |
| YC1 |
0.90846 |
8.4936 |
-12.296 |
32.53 |
-0.63057 |
download these results as csv
Boxplots
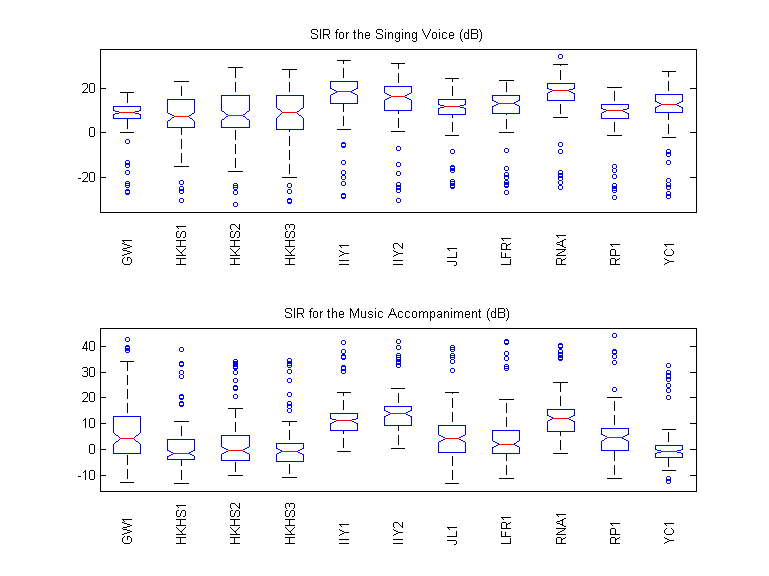
SAR
For the Singing Voice (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
10.398 |
6.6431 |
-13.219 |
19.227 |
11.757 |
| HKHS1 |
4.4392 |
5.1179 |
-16.316 |
17.676 |
5.1547 |
| HKHS2 |
3.6845 |
6.1018 |
-23.638 |
15.233 |
4.4692 |
| HKHS3 |
3.6391 |
5.615 |
-14.303 |
15.068 |
3.2243 |
| IIY1 |
7.7078 |
7.4547 |
-25.591 |
16.613 |
9.6827 |
| IIY2 |
8.5817 |
7.2202 |
-24.222 |
17.066 |
10.487 |
| JL1 |
10.026 |
7.5205 |
-16.962 |
21.028 |
11.47 |
| LFR1 |
4.729 |
5.6625 |
-23.426 |
12.721 |
5.5804 |
| RNA1 |
6.662 |
7.3118 |
-25.659 |
15.083 |
8.9188 |
| RP1 |
9.8241 |
6.5477 |
-13.189 |
24.156 |
11.033 |
| YC1 |
2.9058 |
5.0893 |
-21.403 |
8.872 |
4.0133 |
download these results as csv
For the Music Accompaniment (dB)
| Algorithm |
Mean |
SD |
Min |
Max |
Median |
| GW1 |
8.7701 |
3.3088 |
-2.6918 |
16.204 |
8.6529 |
| HKHS1 |
4.4585 |
4.2757 |
-12.382 |
16.774 |
4.7823 |
| HKHS2 |
4.2321 |
4.22 |
-8.0849 |
14.269 |
4.5204 |
| HKHS3 |
5.3476 |
4.6397 |
-12.255 |
14.438 |
5.794 |
| IIY1 |
5.4262 |
3.1853 |
-2.678 |
15.981 |
5.2362 |
| IIY2 |
5.0379 |
3.325 |
-3.1753 |
16.62 |
5.0873 |
| JL1 |
9.6038 |
3.7963 |
-3.8019 |
17.577 |
10.158 |
| LFR1 |
4.8871 |
3.4349 |
-12.787 |
10.789 |
5.0422 |
| RNA1 |
4.7221 |
3.4545 |
-1.6892 |
15.052 |
4.9501 |
| RP1 |
7.6957 |
3.3901 |
-7.2754 |
14.854 |
7.9782 |
| YC1 |
-1.9525 |
2.8357 |
-12.203 |
6.2045 |
-2.3271 |
download these results as csv
Boxplots
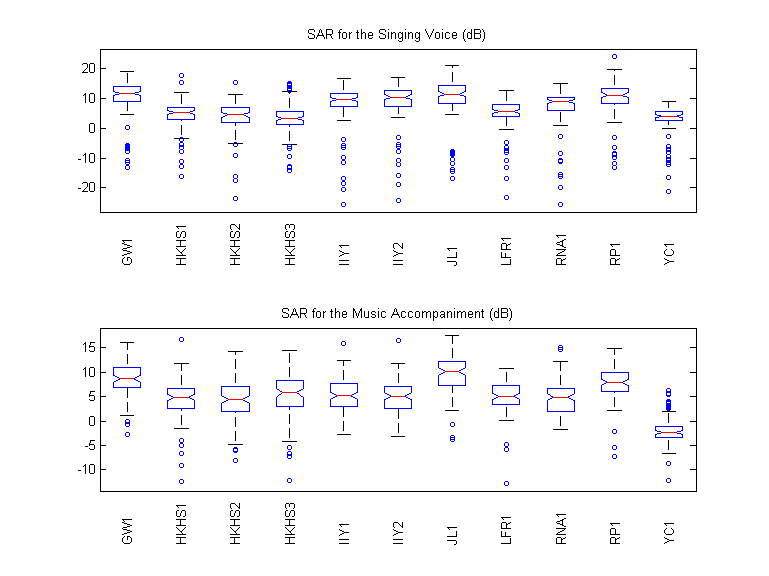
Individual Spectrograms
As the MIREX test set is private, we use three other songs with similar characteristics to demonstrate the algorithms.
Labels
a = input mixture x, b = ground truth voice for x, c = extracted voice from x,
d = input mixture y, e = ground truth voice for y, f = extracted voice from y,
g = input mixture z, h = ground truth voice for z, i = extracted voice from z
Runtime Data
| Submission Code |
Runtime (hh) |
| GW1 |
24 |
| HKHS1 |
06 |
| HKHS2 |
06 |
| HKHS3 |
06 |
| IIY1 |
02 |
| IIY2 |
02 |
| JL1 |
01 |
| LFR1 |
03 |
| RNA1 |
06 |
| RP1 |
01 |
| YC1 |
13 |
download these results as csv













